Akamai friendzoneó a mi bot 😔

El problema
Como muchas personas saben, administro el proyecto STEM Jobs CR desde hace tiempo, el cual consiste en un bot que monitorea continuamente más de 200 bolsas de empleo y envía notificaciones a Telegram, Discord y WhatsApp cuando detecta nuevas publicaciones de puestos de empleo en STEM.
Hace unas semanas mi bot empezó a fallar de forma intermitente, y al revisar los logs me di cuenta que estaba tardando mucho más de lo normal en terminar su ejecución. Además, noté que había muchas instancias del bot ejecutándose en segundo plano, algunas hasta con días de estar “colgadas”, sin terminar nunca.
Después de investigar un poco más, determiné cuál era la bolsa de empleo que estaba causando el problema. El URL de la bolsa de empleo en cuestión funcionaba sin problemas desde el navegador en mi PC personal, lo cual me dejaba dos posibles causas:
- El servidor bloqueó la dirección IP de mi bot: poco probable, ya que en mi PC local pude reproducir el mismo comportamiento que en mi servidor en la nube, enviando requests con código.
- Los requests a la bolsa de empleo ahora requieren un token, cookie y/o header adicional, lo cual explicaría por qué en el navegador no hay problemas.
Teniendo eso en cuenta, empecé a explorar la segunda posibilidad. Copié el request del navegador en formato cURL (usando las herramientas de desarrollador), y ejecuté el request desde la terminal. 
El request funcionó correctamente sin colgarse. Como siguiente paso en la investigación, empecé a quitar headers del request y a reproducirlo para intentar determinar cuál o cuáles eran los headers mínimos necesarios para que el request fuera exitoso.
Aquí encontré otro comportamiento inconsistente: cuando ejecutaba un request con los mismos headers que había copiado del navegador, funcionaba sin problemas, pero al quitar la mayoría de headers los requests seguían siendo exitosos, y si intentaba reproducir el mismo request con pocos headers en una sesión aparte, los requests volvían a fallar. O sea, es como si el servidor tomara en cuenta requests exitosos anteriores en la misma sesión para validar requests nuevos, sin importar los headers de éstos.
Dicho comportamiento me hizo pensar que tal vez la bolsa de empleo ahora estaba detrás de algún control de seguridad, como un WAF por ejemplo, así que consulté los registros DNS del host para saber a qué IP estaba apuntando: 

Tanto la dirección IP como los dominios de los CNAMEs son propiedad de Akamai, lo cual explica tanto el problema inicial de “latencia infinita”, como la inconsistencia al usar requests aparentemente similares en diferentes sesiones de comunicación.
Según Wikipedia, Akamai es una compañía especializada en content delivery network (CDN), ciberseguridad, mitigación de ataques DDoS y servicios en la nube. Y como anécdota personal, hace años tuve un par de entrevistas laborales ahí, y en el proceso me di cuenta que en esa empresa tienen un conocimiento bastante amplio y profundo de cómo funcionan las redes a bajo nivel, con un enfoque especial en el proceso “three-way handshake” del protocolo TCP. Además de esto, recordé que existen técnicas de escaneo de puertos de red y ataques de denegación de servicio que consisten en manipular el proceso de three-way handshake y la funcionalidad general del protocolo TCP para lograr sus objetivos respectivos.
Nota: la técnica de bloqueo de bots usada en este caso se llama “tarpit” (¡gracias a Jose Hernan Perez en LinkedIn por señalarlo!)

Analizando la conexión con Wireshark
Con esa información, decidí usar Wireshark para inspeccionar la conexión de mi bot con el servidor de la bolsa de empleo, para confirmar qué estaba pasando exactamente.
Primero, capturé el comportamiento “normal”, es decir, cuando mi navegador hace el request al servidor de la bolsa de empleo, y recibe la respuesta esperada. 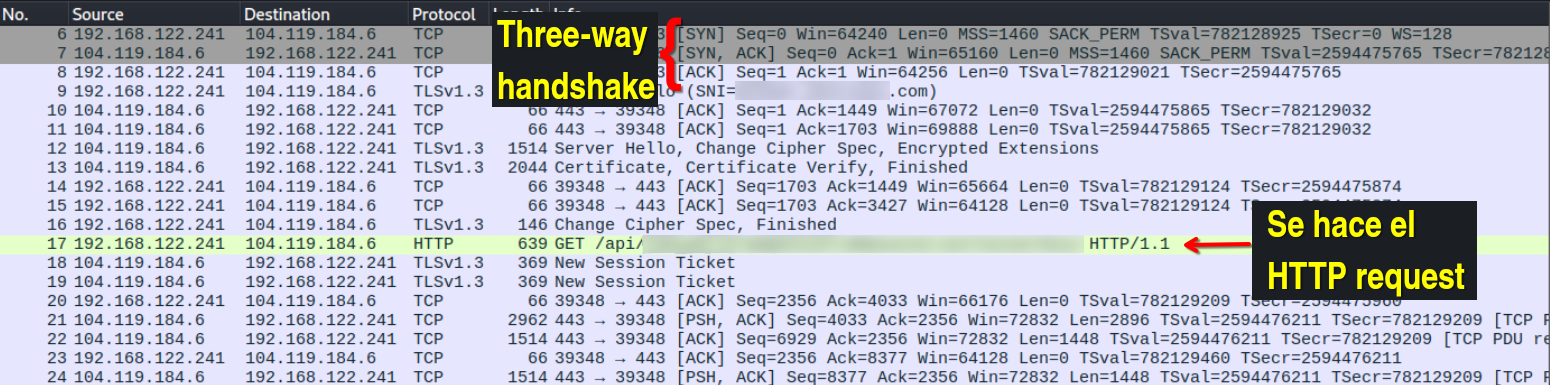 [se omite parte de la comunicación]
[se omite parte de la comunicación] 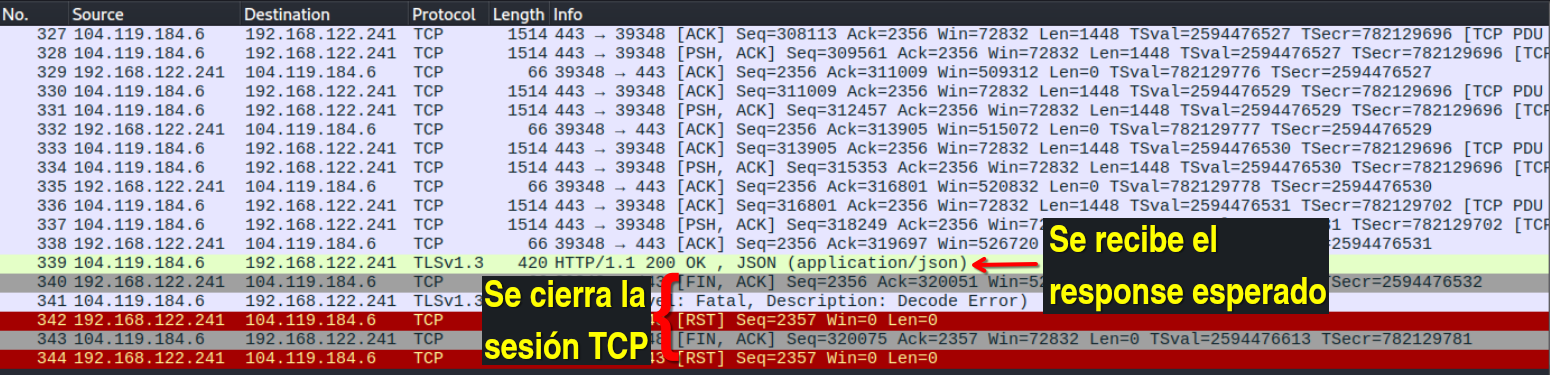
Como se puede ver en las capturas de pantalla, la sesión TCP se establece con un three-way handshake, el cliente (mi navegador) envía el request, el servidor lo recibe y empieza a enviar los datos del mismo. Finalmente, el cliente envía un paquete FIN ACK para cerrar la sesión con el servidor, y la comunicación termina.
Nota: para ver el tráfico HTTPS sin cifrado, utilicé esta guía.
Sin embargo, al hacer un request con el mismo URL pero usando mi bot escrito en Python, la comunicación se desarrolla de forma diferente: 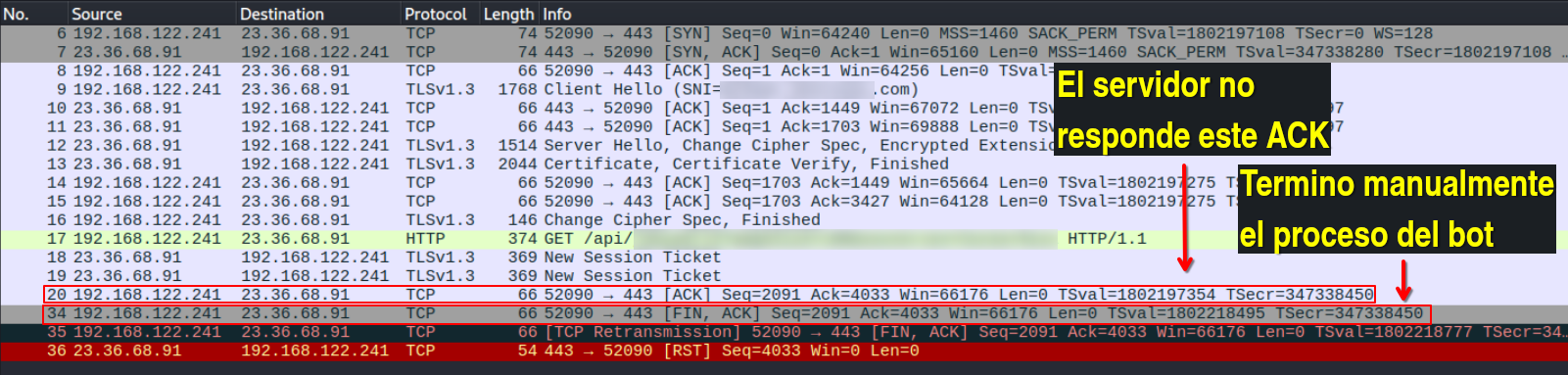
La conexión se establece normalmente igual que en el ejemplo anterior, pero tan pronto como el servidor recibe el HTTP request, deja de responder, sin enviar ningún paquete FIN o RST. Al terminar forzosamente el proceso de mi bot, el mismo envía un FIN ACK al servidor, y el este contesta con un RST, lo cual asumo que significa que el servidor ya había terminado la sesión de su lado, y no tiene “conocimiento” de la sesión que mi cliente había establecido hace unos segundos.
En resumen: cuando el servidor de Akamai recibe un request fuera de lo común, simplemente bota la conexión TCP de su lado, sin dejarle saber al cliente que lo hizo. Esto confirma el comportamiento que sospeché inicialmente.
La solución
Mi bot usa la biblioteca requests, que simplifica enormemente la creación y manipulación de HTTP requests en Python.
Después de investigar más a fondo su funcionamiento, me di cuenta que esta biblioteca no tiene timeouts definidos por defecto, pero dispone del parámetro timeout, el cual se puede usar de dos maneras:
- Si se define un único valor numérico, éste se interpretará como la cantidad máxima de segundos que se esperará, tanto para que la conexión inicial se establezca, como para que el servidor envíe paquetes de respuesta al cliente.
- Definiendo una tupla de valores numéricos, es posible especificar por aparte el tiempo de espera para el
connectinicial y para cadaread.
También es posible especificar None como valor de este parámetro, pero ése es el comportamiento por defecto, como se puede ver en el código fuente de la biblioteca.
Por lo tanto, usando el parámetro timeout, se pueden evitar este tipo de cuelgues “infinitos”:
1
r = requests.get('https://jobs.com/api/', timeout=(3.14, 15))
Después de implementar estos timeouts en mi código, ahora el bot espera nada más 15 segundos después de hacer el HTTP request, y después falla con un error de tipo requests.exceptions.ReadTimeout, lo cual previene que se cuelgue indefinidamente.
PD: Para volver a extraer la información de empleos exitosamente de esa bolsa de empleo, simplemente agregué a mi bot los headers que envía normalmente el navegador cuando hace un request a esa URL 😉